L∞P overview
We strongly recommend reading the fundamentals section if you have not done it before getting started with this section.
The Infinite Loop (L∞P) is an Agile software development methodology inspired by the open-source community and designed to help technology businesses create a culture of trust, ownership, and data-driven continuous experimentation that fosters sustainable product-led growth and high-performance digital product teams.
The Infinite Loop doesn't try to reinvent the wheel; for the most part, it simply takes elements from other methodologies and software development principles.
In Part I, we learned that infinite games are competitions without clear endpoints, and the rules constantly change. The name Infinite Loop refers to "infinite games" to reinforce the idea that the development of a digital product is an infinite game.
The Infinite Loop proposes the creation of product-led teams that use a pull-based system and two backlogs with a focus on different but equally important objectives.
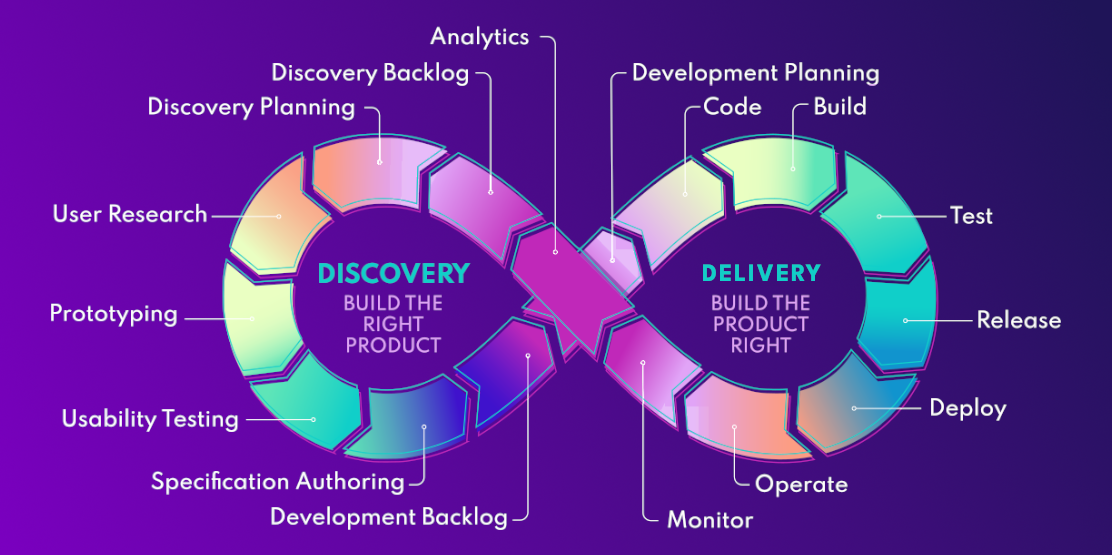
Discovery: build the right product
When we say "discovery," we typically refer to understanding customers' pain points, identifying potential ways you could solve those problems, and validating whether the product you build will solve those problems.
Understanding problems and opportunities before you set out to solve them helps reduce risk and uncertainty around investing time and money. It also gives you a solid foundation to launch and grow your product and business once you're ready.
Discovery aims to understand the business goals and user needs. The goal is to design solutions to address their critical challenges before committing resources to development. However, this doesn't mean that developers are not involved in Discovery. Developers should be engaged in direct conversations with the customer. Also, sometimes the only way to remove unknowns, especially technical unknowns, is to build a prototype that might require development resources.
The goal of product discovery is not necessary to ship features. Instead, it's to promote an environment of learning that will help you prioritize the most learning for the least amount of effort, helping you consistently and incrementally improve your products and features. Ask yourself: what's the smallest thing we can do today to learn something new that would guide us in making decisions? By using this framework and following its steps, product teams can create an environment of continuous learning that leads to genuinely excellent products.
The goal is to ensure we build the right product by eliminating risk (unknowns), including:
Value risk (whether customers will buy it or users will choose to use it)
Usability risk (whether users can figure out how to use it)
Feasibility risk (whether our engineers can build what we need with the time, skills and technology we have)
Business viability risk (whether this solution also works for the various aspects of our business)
The discovery process isn't always smooth. Product discovery isn't a linear process; it's an iterative process that changes as you learn more about user needs and reduce uncertainty.
The Discovery should use good practices and techniques that traditionally have been part of the Lean UX and Product-led growth movements.
- Research
- Ideation
- Mental models
- Sketches
- Personas
- Tasks models
- Flow models
- User journey mapping
- Affinity clustering
- Storyboards
- Prototypes
- Wireframes
- Value propositions
- Landing pages
- Hypotheses
- A/B testing
- MMF
- Analytics
- Usability testing
- Feedback system
- Customer meetings
- Collaborative workshops
You can learn more about these techniques by reading the official guide. The guide is available for free on the Design Sprint Kit.
The Discovery should collect data (e.g. customer feedback, usability testing) so that the product team gains enough confidence to commit; they work together to finalise a specification that can be included in the Delivery backlog.
Delivery: build the product right
After validating our solution ideas with real user data, developers can implement the application. There are no arbitrary deadlines and inaccurate estimates; we trust the developers are pragmatic and reach the right compromise between providing value and managing technical debt. At this point, our developers are perfectly aware of what they need to get done; they are motivated to deliver value to our customers.
The developers only need us to leave them alone for a few hours so they can get into the flow and get work done. They have a high level of ownership and are responsible for implementing, releasing and operating the code changes. They constantly search for ways to leverage automation to optimize their feedback loops and improve efficiency. The goal is to build the product right.
The Delivery should implement The Three Ways principles and use standard DevOps techniques such as the following:
- Continuous integration (CI)
- Continuous delivery (CD)
- Infrastructure as Code
- Chaos engineering
- Feature flags and A/B testing
- DevSecOps
- Automated Recovery
- User Telemetry
- Blue-green deployments
- Canary releases
- Configuration management
- Log management
- Performance monitoring
- Immutable infrastructure
While working on infrastructure tasks, we must remember that technology is not a goal but a tool. Having the most robust continuous integration and continuous delivery pipelines the world has ever seen is pointless if we build a product that fails to provide value to our customers. We must approach infrastructure tasks with pragmatism and reach a compromise between the ideal infrastructure and delivering customer value. One technique that helps to remain pragmatic is always to ask yourself how this work will improve your customers' lives.
One of the most critical characteristics of high-performance teams is psychological safety. Automation can contribute to this sense of security. The goal of automation is to provide developers with confidence and a sense of safety so they can move faster. When developers are confident that the automated tests and the CI/CD will be able to detect any errors, they are less afraid to attempt to contribute.
Continuous delivery of value
The Infinite Loop is meant to be iterative, not linear. The Infinite Loop divides the flow of work into Discovery and Delivery. The Discovery backlog contains user stories that can be pulled into the workboard. When the UX designers and developers understand the problem they are trying to solve and the proposed solution, they write a spec that becomes an item in the Delivery backlog.
However, Discovery and Delivery are not linear. The process should be iterative. Some discovery work takes a few hours, and others can take longer, but it is an ongoing process of ideation, validation and removing unknowns. We pick one customer pain point at a time and use Discovery to mitigate the risk before proceeding to development. Often the same pain point will go through multiple discovery/development iterations. The Discovery might involve prototyping, surveys, and data mining in early iterations, but successive iterations probably include data analytics and A/B testing in production (doing this in production requires Delivery)
Rather than a Discovery "Phase" where we spend several weeks of validated product backlog items and deliver them to engineering, teams should embrace continuous product discovery – where we are constantly identifying, validating and describing new product backlog items. Discovery feeds Delivery, and Delivery feeds Discovery. They aren't two distinct phases. You can't have one without the other. The process is iterative and infinite, not linear. Discovery and Delivery should ultimately lead to an infinite and continuous delivery of value.